Link to LessWrong post here.
Six (and a half) intuitions for KL divergence
KL-divergence is a topic which crops up in a ton of different places in information theory and machine learning, so it's important to understand well. Unfortunately, it has some properties which seem confusing at a first pass (e.g. it isn't symmetric like we would expect from most distance measures, and it can be unbounded as we take the limit of probabilities going to zero). There are lots of different ways you can develop good intuitions for it that I've come across in the past. This post is my attempt to collate all these intuitions, and try and identify the underlying commonalities between them. I hope that for everyone reading this, there will be at least one that you haven't come across before and that improves your overall understanding!
One other note - there is some overlap between each of these (some of them can be described as pretty much just rephrasings of others), so you might want to just browse the ones that look interesting to you. Also, I expect a large fraction of the value of this post (maybe >50%) comes from the summary, so you might just want to read that and skip the rest!
Summary
1. Expected surprise
how much more surprised you expect to be when observing data with distribution , if you falsely believe the distribution is vs if you know the true distribution
2. Hypothesis Testing
the amount of evidence we expect to get for over in hypothesis testing, if is true.
3. MLEs
If is an empirical distribution of data, is minimised (over ) when is the maximum likelihood estimator for .
4. Suboptimal coding
the number of bits we're wasting, if we try and compress a data source with distribution using a code which is actually optimised for (i.e. a code which would have minimum expected message length if were the true data source distribution).
5A. Gambling games - beating the house
the amount (in log-space) we can win from a casino game, if we know the true game distribution is but the house incorrectly believes it to be .
5B. Gambling games - gaming the lottery
the amount (in log-space) we can win from a lottery if we know the winning ticket probabilities and the distribution of ticket purchases .
6. Bregman divergence
is in some sense a natural way of measuring of how far is from if we are using the entropy of a distribution to capture how far away it is from zero (analogous to how is a natural measure of the distance between vectors and , if we're using to capture how far the vector is from zero).
Common theme for most of these:
measure of how much our model differs from the true distribution . In other words, we care about how much and differ from each other in the world where P is true, which explains why KL-div is not symmetric.
1. Expected Surprise
For a random variable with probability distribution , the surprise (or surprisal ) is defined as . This is motivated by some simple intuitive constraints we would like to have on any notion of "surprise":
- An event with probability has no surprise
- Lower-probability events are strictly more surprising
- Two independent events are exactly as surprising as the sum of those events' surprisal when independently measured
In fact, it's possible to show that these three considerations fix the definition of surprise up to a constant multiple.
From this, we have another way of defining entropy - as the expected surprisal of an event:
Now, suppose we (erroneously) believed the true distribution of to be , rather than . Then the expected surprise of our model (taking into account that the true distribution is ) is:
and we now find that:
In other words, KL-divergence is the difference between the expected surprise of your model, and the expected surprise of the correct model (i.e. the model where you know the true distribution ). The further apart is from , the worse the model is for , i.e. the more surprised it should expect to get by reality.
Furthermore, this explains why isn't symmetric, e.g. why it blows up when but not when . In the former case, your model is assigning very low probability to an event which might happen quite often, hence your model is very surprised by this. The latter case doesn't have this property, and there's no equivalent story you can tell about how your model is frequently very surprised. [1]
2. Hypothesis Testing
Suppose you have two hypotheses: a null hypothesis which says that , and an alternative hypothesis which says that . Suppose the null is actually true. A natural hypothesis test is the likelihood ratio test, i.e. you reject if the observation is in the critical region:
for some constant which determines the size of the test. Another way of writing this is:
We can interpret the value as (a scalar multiple of [2] ) the bits evidence we get for over . In other words, if happens twice as often under distribution than distribution , then the observation is a single bit of evidence for over .
is (a scalar multiple of) the expected bits of evidence we get for over , where the expectation is over the null hypothesis . The closer and are, the more we should expect it to be hard to distinguish between them - i.e. when is true, we shouldn't expect reality to provide much evidence for rather than being true.
3. MLEs
This one is a bit more maths-heavy than the others, so ymmv on how enlightening it is!
Suppose is the empirical distribution of data , which are each iid with distribution , and is a statistical model parameterised by . Our likelihood function is:
By the law of large numbers, almost surely. This is the cross entropy of and . Also note that if we subtract this from the entropy of , we get . So minimising the cross entropy over is equivalent to maximising .
Our maximum likelihood estimator is the parameter which maximises , and we can use some statistical learning theory plus a lot of handwaving to argue that (i.e. we've swapped around the limit and argmin operators). In other words, maximum likelihood estimation is equivalent to minimising KL-divergence. If is large, this suggests that will not be a good model for data generated from the distribution .
4. Suboptimal Coding
Source coding is a huge branch of information theory, and I won't go through all of that in this post. There are several online resources that do a good job of explaining it. To recap the key idea that will be important here:
If you're trying to transmit data from some distribution over a binary channel, you can assign particular outcomes to strings of binary digits in a way which minimises the expected number of digits you have to send. For instance, if you have three possible events with probability (0.8, 0.1, 0.1), then it makes sense to use a code like (0, 10, 11) for this sequence, because you'll find yourself sending the shorter codes with higher probability.
In the limit for a large number of possible values for (provided some other properties hold), the optimal code [3] will represent outcome with a binary string of length .
From this, the intuition for KL divergence pops neatly out. Suppose you erroneously believed that , and you designed an encoding that would be optimal in this case. The expected number of bits you'll have to send per message is:
and we can immediately see that KL-divergence is (up to a scale factor) the difference in expected number of bits per event you'll have to send with this suboptimal code, vs the number you'd expect to send if you knew the true distribution and could construct the optimal code. The further apart and are, the more bits you're wasting on average by not sending the optimal code. In particular, if we have a situation like , this means our code (which is optimised for ) will assign a very long codeword to outcome since we don't expect it to occur often, and so we'll be wasting a lot of message space by frequently having to use this codeword.
5A. Gambling Games - Beating the House
Suppose you can bet on the outcome of some casino game, e.g. a version of a roulette wheel with nonuniform probabilities. First, imagine the house is fair, and pays you times your original bet if you bet on outcome (this way, any bet has zero expected value: because betting on outcome means you expect to get returned to you). Because the house knows exactly what all the probabilities are, there's no way for you to win money in expectation.
Now imagine the house actually doesn't know the true probabilities , but you do. The house's mistaken belief is , and so they pay people for event even though this actually has probability . Since you know more than them, you should be able to profit from this state of affairs. But how much can you make?
Suppose you have $1 to bet. You bet on outcome , so . Let be your expected winnings. It is more natural to talk about log winnings, because this describes how your wealth grows proportionally over time. Your expected log winnings are:
It turns out that, once you perform a simple bit of optimisation using the Lagrangian:
then you find the optimal betting strategy is (this is left as an exercise to the reader!). Your corresponding expected winnings are:
in other words, the KL divergence represents the amount you can win from the casino by exploiting the difference between the true probabilities and the house's false beliefs . The closer and are, the harder it is to profit from your extra knowledge.
Once again, this framing illustrates the lack of symmetry in the KL-divergence. If , this means the house will massively overpay you when event happens, so the obvious strategy to exploit this is to bet a lot of money on (and will correspondingly be very large). If , there is no corresponding way to exploit this (except to the extent that this suggests we might have for some different outcome ).
5B. Gambling Games - Gaming the Lottery
This is basically the same as (5A), but it offers a slightly different perspective. Suppose a lottery exists for which people can buy tickets, and the total amount people spend on tickets is split evenly between everyone who bought a ticket with the winning number (realistically the lottery organisers would take some spread, but we assume this amount is very small). If every ticket is bought the same number of times, then there's no way to make money in expectation. But suppose people have a predictable bias (e.g. buying round numbers, or numbers with repeated digits) - then you might be able to make money in expectation by buying the less-frequently-bought tickets, because when you win you generally won't have as many people you'll have to split the pot with.
If you interpret as the distribution of people buying each ticket (which is known to you), and is the true underlying distribution of which ticket pays out (also known), then this example collapses back into the previous one - you can use optimisation to find that the best way to purchase tickets is in proportion to , and the KL-divergence is equal to your expected log winnings.
To take this framing further, let's consider situations where is not known to you on a per-number basis, but the overall distribution of group-sizes-per-ticket-number is known to you. For instance, in the limit of a large number of players and of numbers you can approximate the group size as a Poisson distribution. If each ticket has the same probability of paying out, then you can make profit in expectation by buying one of every ticket (where is the uniform distribution, and is the Poisson distribution). Interestingly, this strategy of "buying the pot" is theoretically possible for certain lotteries, for instance in the Canadian 6/49 Lotto (see a paper analysing this flaw here ). However, there are a few reasons this tends not to work in real life, such as:
- The lottery usually takes a sizeable cut
- There are lottery restrictions (e.g. ticket limits)
- Buying the pool is prohibitively expensive (organising and funding a syndicate to exploit this effect is hard!)
6. Bregman Divergence
Bregman divergence is pretty complicated in itself, and I don't expect this section to be illuminating to many people (it's still not fully illuminating to me!). However, I thought I'd still leave it in because it does offer an interesting perspective.
If you wanted to quantify how much two probability distributions diverge, the first thing you might think of is taking a standard norm (e.g. ) of the difference between them. This has some nice properties, but it's also unsatisfactory for a bunch of reasons. For instance, it intuitively seems like the distance between the Bernoulli distributions with and should be larger than that between and . [4]
It turns out that there's a natural way to associate any convex function with a measure of divergence. Since tangents to convex functions always lie below them, we can define Bregman divergence as the amount by which is greater than the estimate for it you would get by fitting a tangent line to at and using it to linearly extrapolate to .
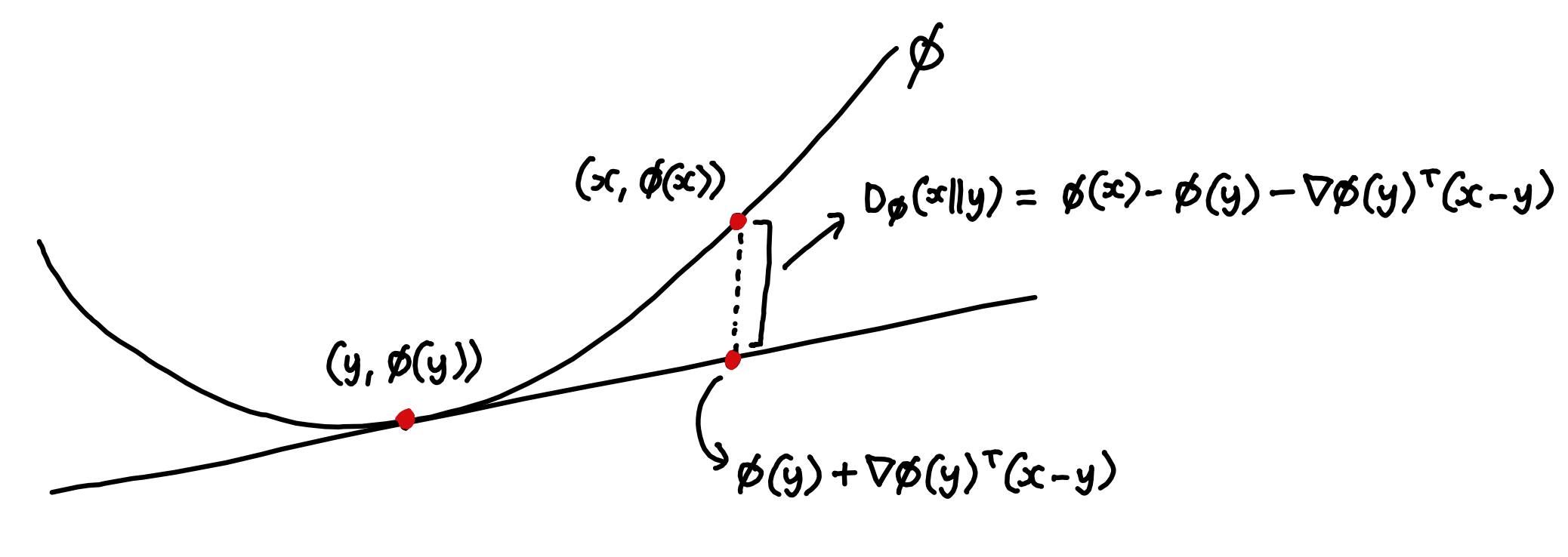
To do some quick sanity checks for Bregman divergence - if your convex function is the norm squared, then the divergence measure you get is just the squared norm of the vector between your points:
This is basically what you'd expect - it shows you that when the norm is the natural way to measure how far away something is from zero (i.e. how large it is), then the norm of the vector between two points is the natural way to measure how far one point is from another.
Now, lets go back to the case of probability distributions. Is there any convex function which measures, in some sense, how far away a probability distribution is from zero? Well, one thing that seems natural is to say that "zero" is any probability distribution where the outcome is certain - in other words, zero entropy. And it turns out entropy is concave, so if we just take the negative of entropy then we get a convex function. Slap that into the formula for Bregman divergence and we get:
There's no lightning-bolt moment of illumination from this framing. But it's still interesting, because it shows that different ways of measuring the divergence between two points can be more natural than others, depending on the space that we're working in, and what it represents. Euclidean distance between two points is natural in probability space, when zero is just another point in that space. But when working on the probability simplex, with entropy being our chosen way to measure a probability distribution's "difference from zero", we find that is in some sense the most natural choice.
Final Thoughts
Recapping these, we find that being large indicates:
- Your model will be very surprised by reality
- You expect to get a lot of evidence in favour of hypothesis over , if is true
- is a poor model for observed data
- You would be wasting a lot of message content if you tried to encode optimally while falsely thinking the distribution was
- You can make a lot of money in betting games where other people have false beliefs , but you know the true probabilities
- (this one doesn't have as simple a one-sentence summary!)
Although (4) might be the most mathematically elegant, I think (1) cuts closest to a true intuition for .
To summarise what all of these framings have in common:
measure of how much our model differs from the true distribution . In other words, we care about how much and differ from each other in the world where P is true, which explains why KL-div is not symmetric.
To put this last point another way, "doesn't care" when (assuming both probabilities are small), because even though our model is wrong, reality doesn't frequently show us situations in which our model fails to match reality. But if then the outcome will occur more frequently than we expect, consistently surprising our model and thereby demonstrating the model's inadequacy.
- ^ Note that the latter case might imply the former case, e.g. if then we are actually also in the former case, since . But this doesn't always happen; it is possible to have asymmetry here. For instance, if P = (0.1, 0.9) and Q = (0.01, 0.99), then we are in the former case but not the latter. If is true, then 10% of the time model is extremely surprised, because an event happens that it ascribes probability 1% to - which is why is very large. But if is true, reality presents model with no surprises as large as this - hence is not as large.
- ^ The scalar multiple part is because we're working with natural log, rather than base 2.
- ^ Specifically, the optimal decodable code - in other words, your set of codewords needs to have the property that you could string together any combination of them and it's possible to decipher which codewords you used. For instance,
(0, 10, 11)has this property, but(0, 10, 01)doesn't, because the string010could have been produced from0 + 10or01 + 0. - ^ One way you could argue that a distance measure should have this property is to observe that the former two distributions have much lower variance than the latter two. So if you observe a distribution which is either or , you should expect it to take much less time to tell which of the two distributions you're looking at than if you were trying to distinguish between and .